
1.原代码流程解释
原代码在载入视频的时候,会开启n个多线程来载入视频帧,其中n是视频流的数量。然后将视频帧送入到识别线程中,经过预处理、识别、后处理。流程图如下:
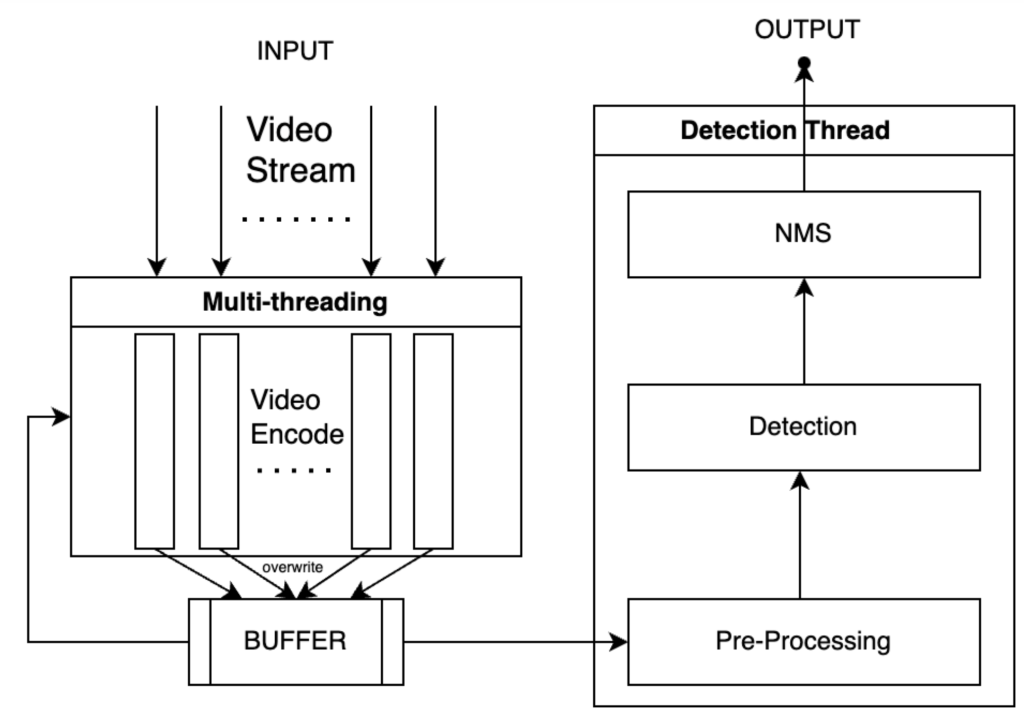
我们可以看到,我们开设了n个线程来处理n个流,然后每一个线程将编码的结果放入到BUFFER中,而后再次进入编码线程中捕获下一帧,如果BUFFER中有图片,直接覆盖上一帧所捕获的图片。另外一个线程从BUFFER内取得数据,然后经过Pre-Processing 模块,Pre-Processing模块中将 raw data 逐张执行letterbox处理并大包围batch的tensor,并传入cuda设备中,Detection使用GPU并行检测后再做NMS。
2. 缺点分析与解决方案
1. 无效数据处理
在编码后,我们放入到BUFFER中,如果识别线程还没有来得及取走BUFFER中的图片,那么程序会再次调用CPU来编码视频流,然后覆盖BUFFER中的图片,那么我们上一次做的编码就浪费了。
所以我们应该在BUFFER没被取走的时候做一个线程阻塞,这样就不会占用CPU资源,从而可以把资源释放出来给识别线程,可以一定程度上家属识别过程。
2. 串行的预处理
在Pre-Processing处理阶段,原代码将 raw data 逐张送入letterBox中作处理,这是串行处理的过程,这也是导致性能差的一个原因之一。
所以我们将预处理流程加入到多线程编码视频流过程之后,从而实现利用多线程加速处理。
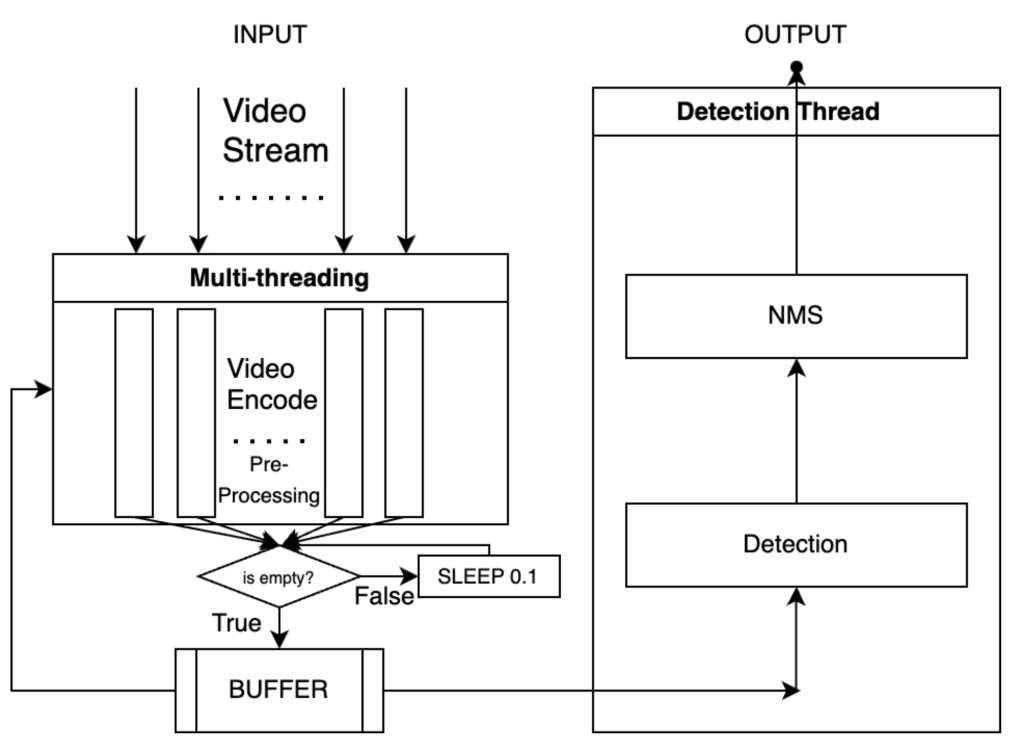
3. 架构分析
在我们优化的过程中,我们进行了优化了处理的流程架构,我们将预处理移动到了多线程的视频流编码后,利用多线程来进行预处理,同时避免了频繁创建线程所带来的时间消耗。 另外在处理完成之后判断BUFFER是否为空,如果为空我们就阻塞线程,从而释放CPU资源给识别线程,从而提高效率。
4. 代码修订处
以88服务器为例,我们首先输入下面代码找到文件目录位置
>>> import ultralytics
>>> ultralytics.__file__
'/usr/local/soft/conda3/envs/yolo8/lib/python3.8/site-packages/ultralytics/__init__.py'其中,’/usr/local/soft/conda3/envs/yolo8/lib/python3.8/site-packages/ultralytics’ 便是目录文件夹。
4.1 loaders.py的文件修改
我们打开服务器的这个文件夹,打开./data/loaders.py,如下图所示:

首先,我们给LoadStreams类(34行左右)的init创建一个的letterbox方法,也就是预处理函数,代码如下:
from ultralytics.data.augment import LetterBox
class LoadStreams:
def __init__(self, sources="file.streams", vid_stride=1, buffer=False):
"""Initialize instance variables and check for consistent input stream shapes."""
torch.backends.cudnn.benchmark = True # faster for fixed-size inference
self.buffer = buffer # buffer input streams
self.running = True # running flag for Thread
self.mode = "stream"
self.vid_stride = vid_stride # video frame-rate stride
# ************ create preprocessing function ************ #
self.letterbox = LetterBox([736, 1280],auto = False,stride= 32)然后修改LoadStreams类下的update方法(大约在119行左右),修改为如下方法:
def update(self, i, cap, stream):
"""Read stream `i` frames in daemon thread."""
n, f = 0, self.frames[i] # frame number, frame array
while self.running and cap.isOpened() and n < (f - 1):
if len(self.imgs[i]) < 2: # keep a <=30-image buffer
n += 1
cap.grab() # .read() = .grab() followed by .retrieve()
if n % self.vid_stride == 0:
success, im = cap.retrieve()
# ************ PreProcessing while encode video ************ #
im = self.letterbox(image = im)
im = torch.from_numpy(im).to('cuda')
# *********************************************************** #
if not success:
im = np.zeros(self.shape[i], dtype=np.uint8)
LOGGER.warning("WARNING ⚠️ Video stream unresponsive, please check your IP camera connection.")
cap.open(stream) # re-open stream if signal was lost
if self.buffer:
self.imgs[i].append(im)
else:
self.imgs[i] = [im]
else:
# LOGGER.warning("WARNING ❌ OUT OFF BUFF")
time.sleep(0.01) # wait until the buffer is empty
4.1 predictor.py的文件修改
接着打开./data/predictor.py,如下图所示:
修改BasePredictor类(65行左右)下的preprocess方法(117行左右)为如下:
def preprocess(self, im):
"""
Prepares input image before inference.
Args:
im (torch.Tensor | List(np.ndarray)): BCHW for tensor, [(HWC) x B] for list.
"""
not_tensor = not isinstance(im, torch.Tensor)
is_list = not isinstance(im[0], torch.Tensor)
if not_tensor:
if is_list:
# ensure other type can be preprocessing as before
im = np.stack(self.pre_transform(im))
im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)
im = np.ascontiguousarray(im) # contiguous
im = torch.from_numpy(im)
else:
# if is video stream, we don't preprocessing in here,one change BHWC to BCHW
im = torch.stack(im).permute(0, 3, 1, 2)
im = im.to(self.device)
im = im.half() if self.model.fp16 else im.float() # uint8 to fp16/32
if not_tensor:
im /= 255 # 0 - 255 to 0.0 - 1.0
return im
留言