
内容纲要
机器学习各种评价指标
1. 混淆矩阵
混淆矩阵(Confusion Matrix)是在机器学习和统计学中用于评估分类模型性能的一种表格形式的工具。它提供了对模型预测结果的详细分析,可以展示模型在不同类别上的分类正确性和错误性。
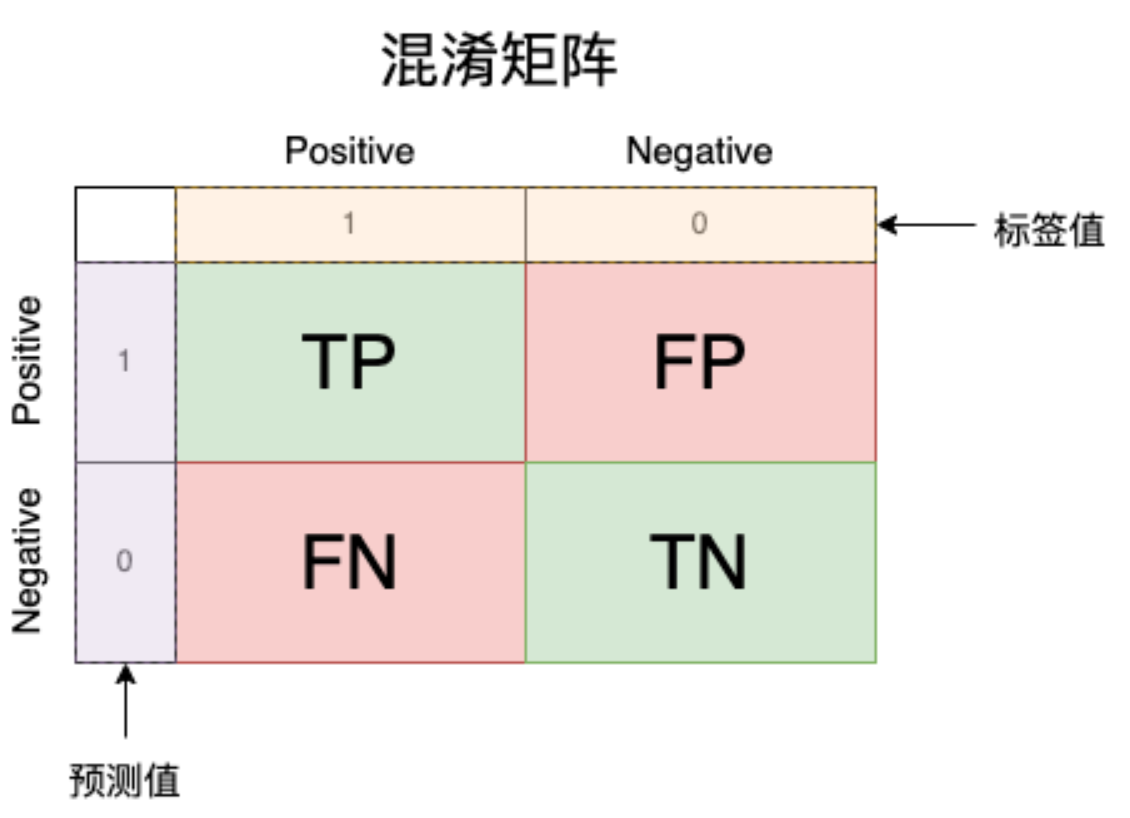
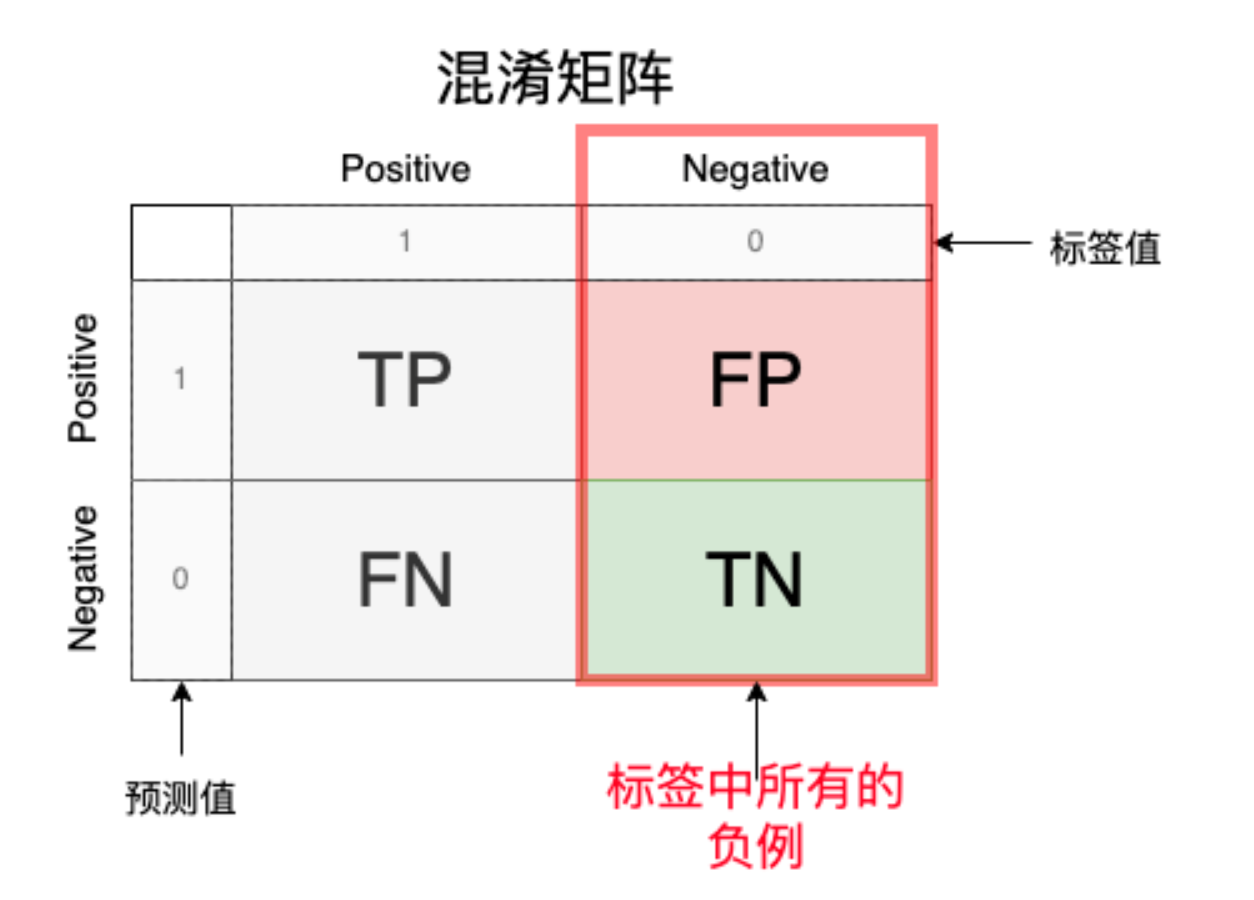
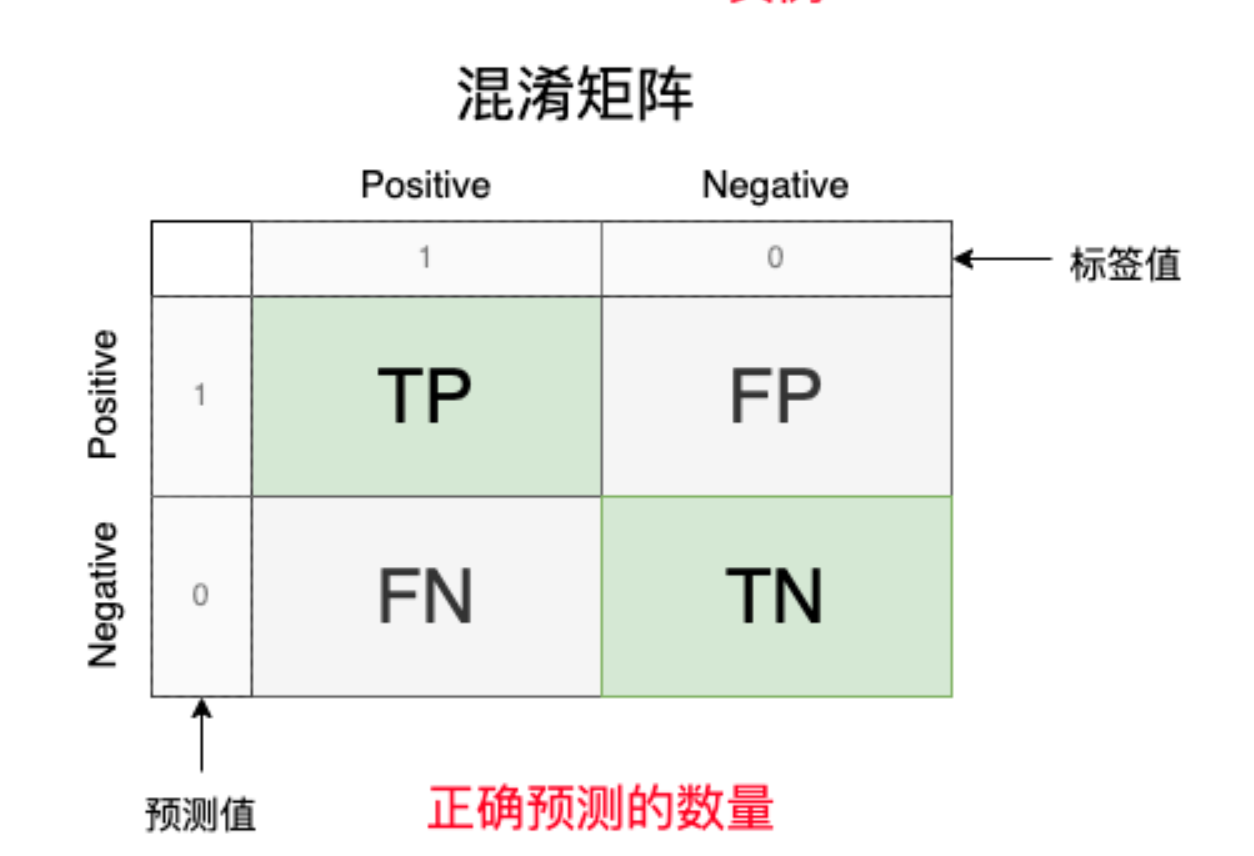
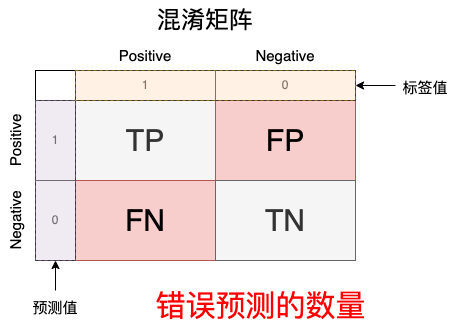
他的形状如上图所示,其中黄色部分为标签的值,紫色部分为模型预测的值,中间有TP、FP、FN、TN是对应的数量。那么TP、FP、FN、TN分别是什么呢?我们通过下图解析:

通过这个例子,我们就可以列出所有的情况,其中后者是对于预测结果来讲的:
- TP: True Positive(真的正例):模型将正例预测为正例的数量,真的正例的数量。
- FN: False Negative(假的反例):模型将正例预测为反例的数量,假的反例的数量。
- FP: False Positive(假的正例):模型将反例预测为正例的数量,假的正例的数量。
- TN: True Negative(真的反例):模型将反例预测为反例的数量,真的反例的数量。
我们对这个矩阵分区块讨论,查看各个区块的意义:
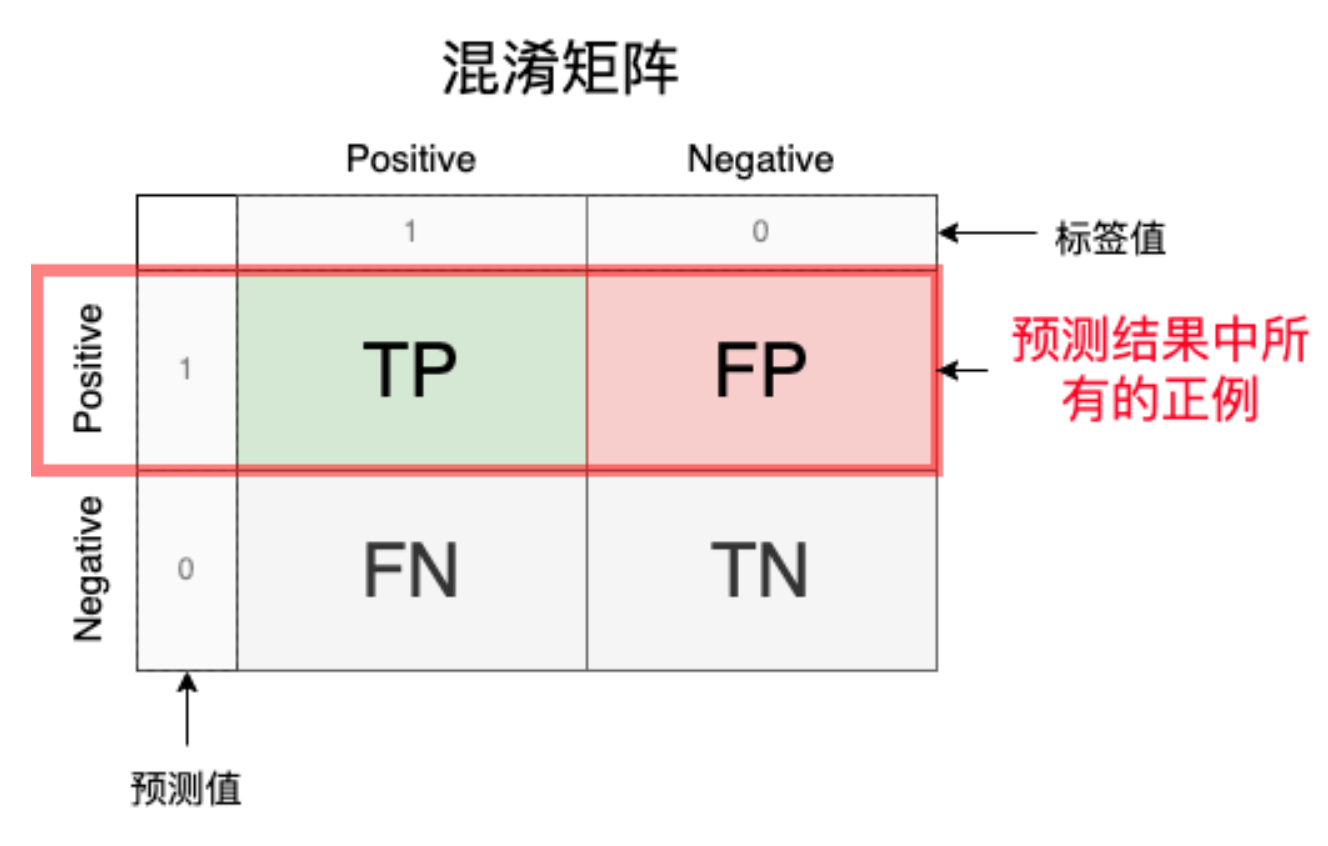
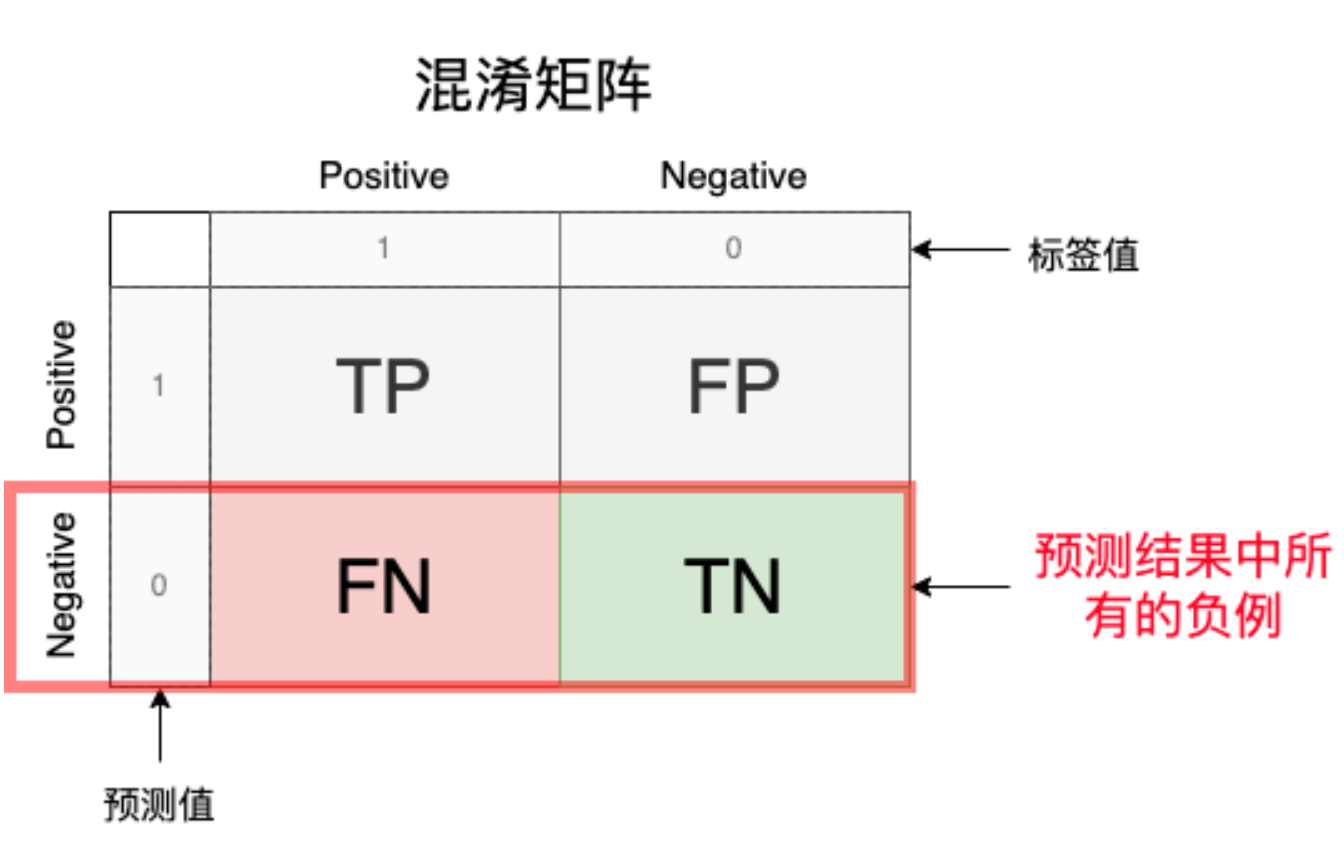
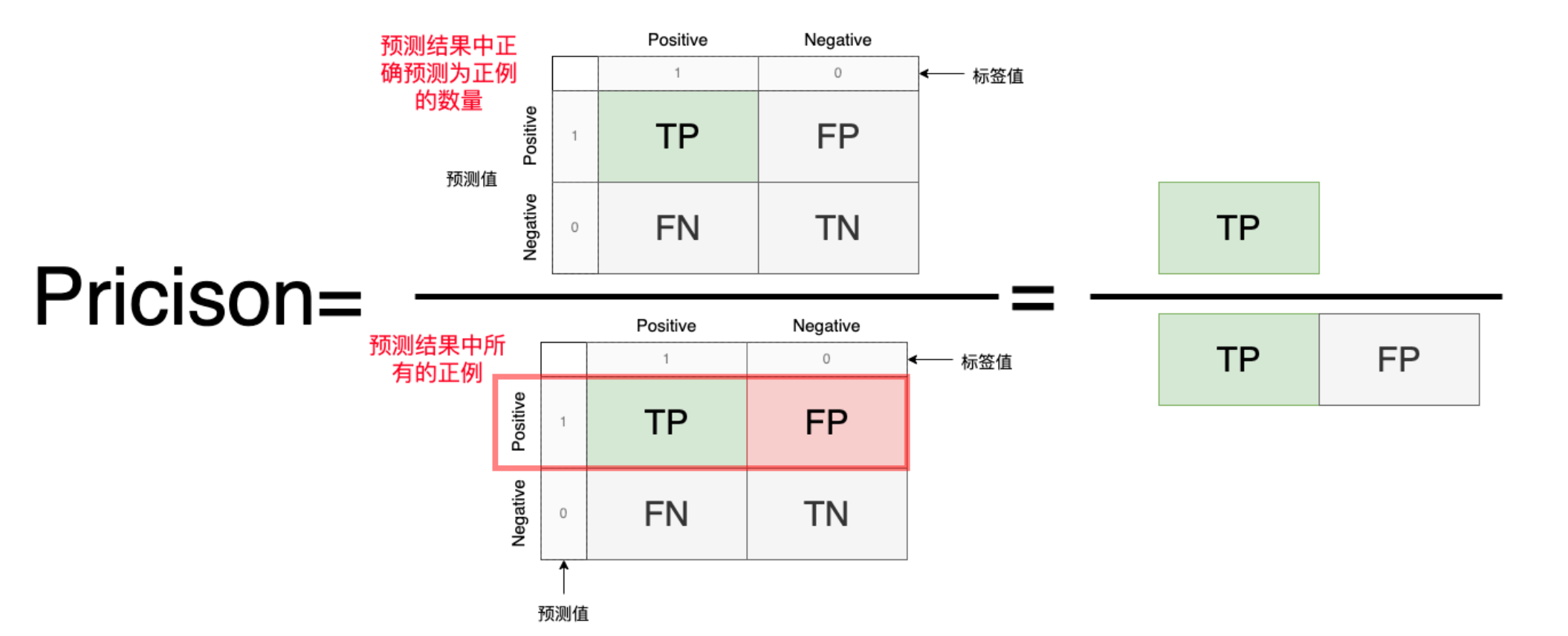
2.Precision(精确度)
模型预测为正例的样本中真正为正例的比例,反映的是在所有检查出来阳性的样本中,正确的比例是多少。
Precison=\frac{预测为正例}{预测中所有的正例}=\frac{TP}{TP+FP}
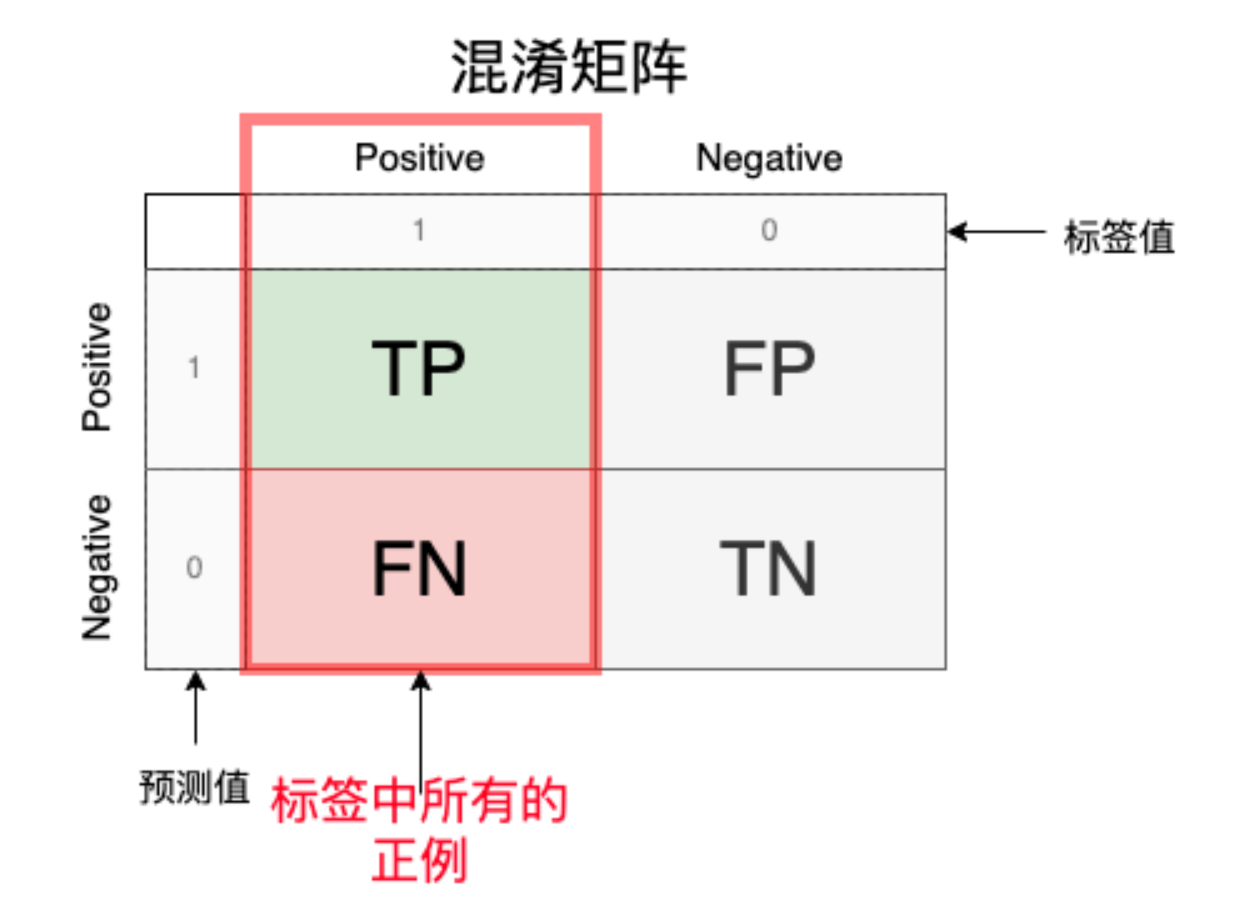
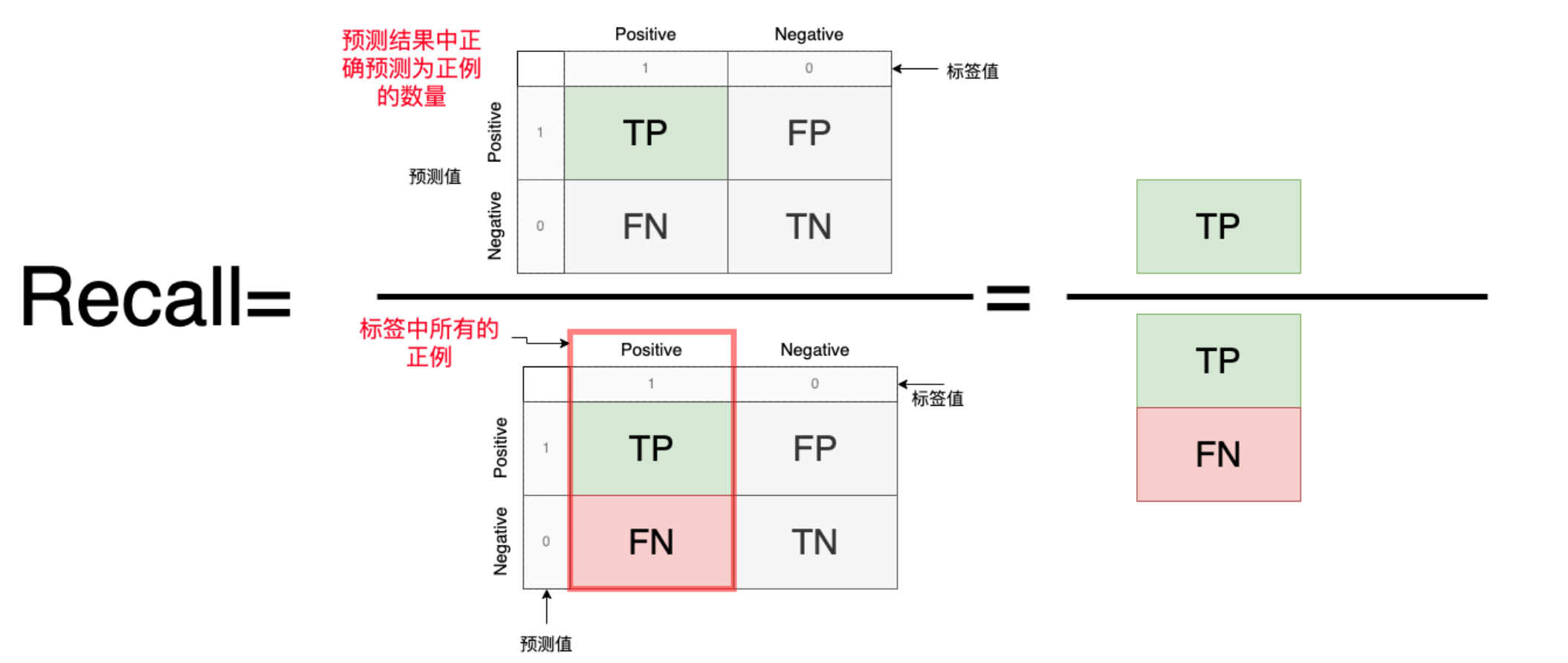
3. Recall(召回率)
Recall衡量了模型正确识别出的正样本(真阳性)在所有实际正样本中的比例。
Recall=\frac{预测为正例}{标签中所有的正例子}=\frac{TP}{TP+FN}
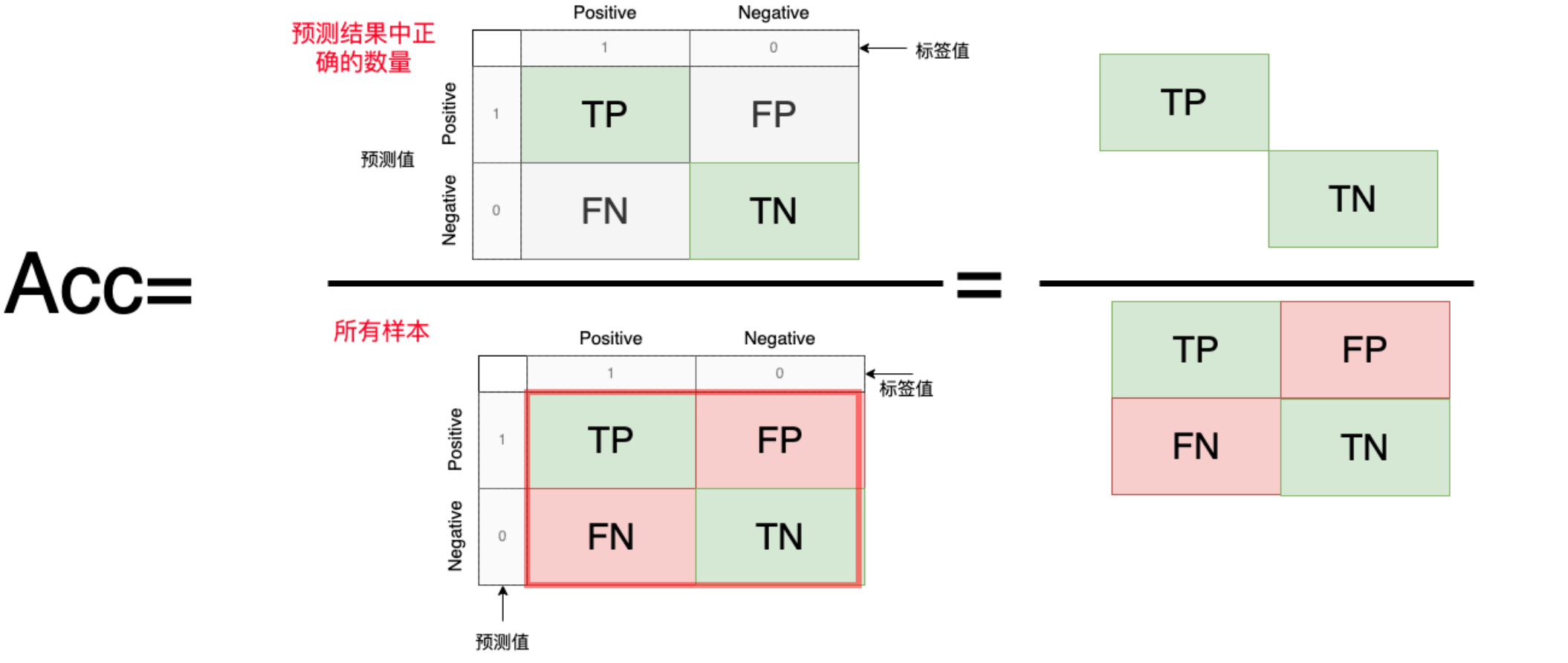
4. Accuracy(准确率)
它表示在所有样本中,分类模型正确预测的样本数占总样本数的比例。
Acc = \frac{正确预测数量}{所有样本数量}=\frac{TP+TN}{TP+FP+FN+TN}
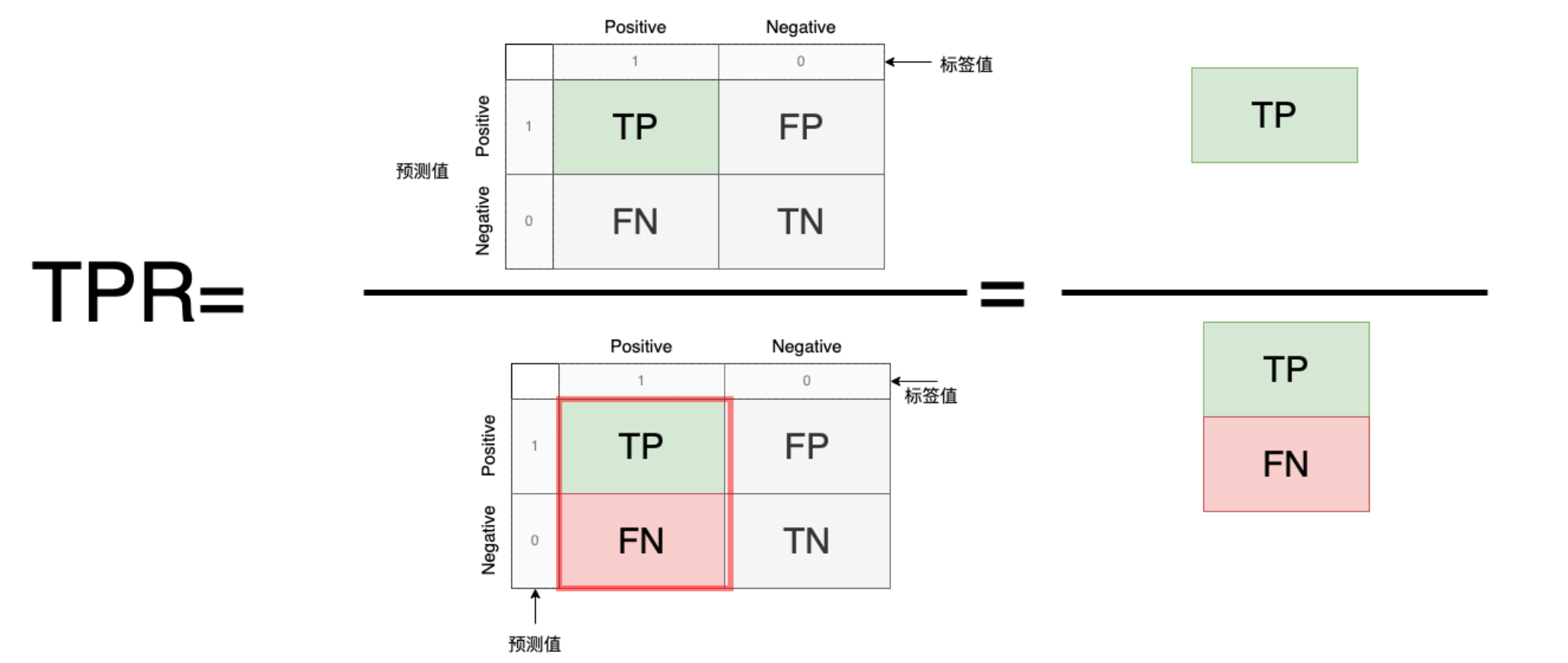
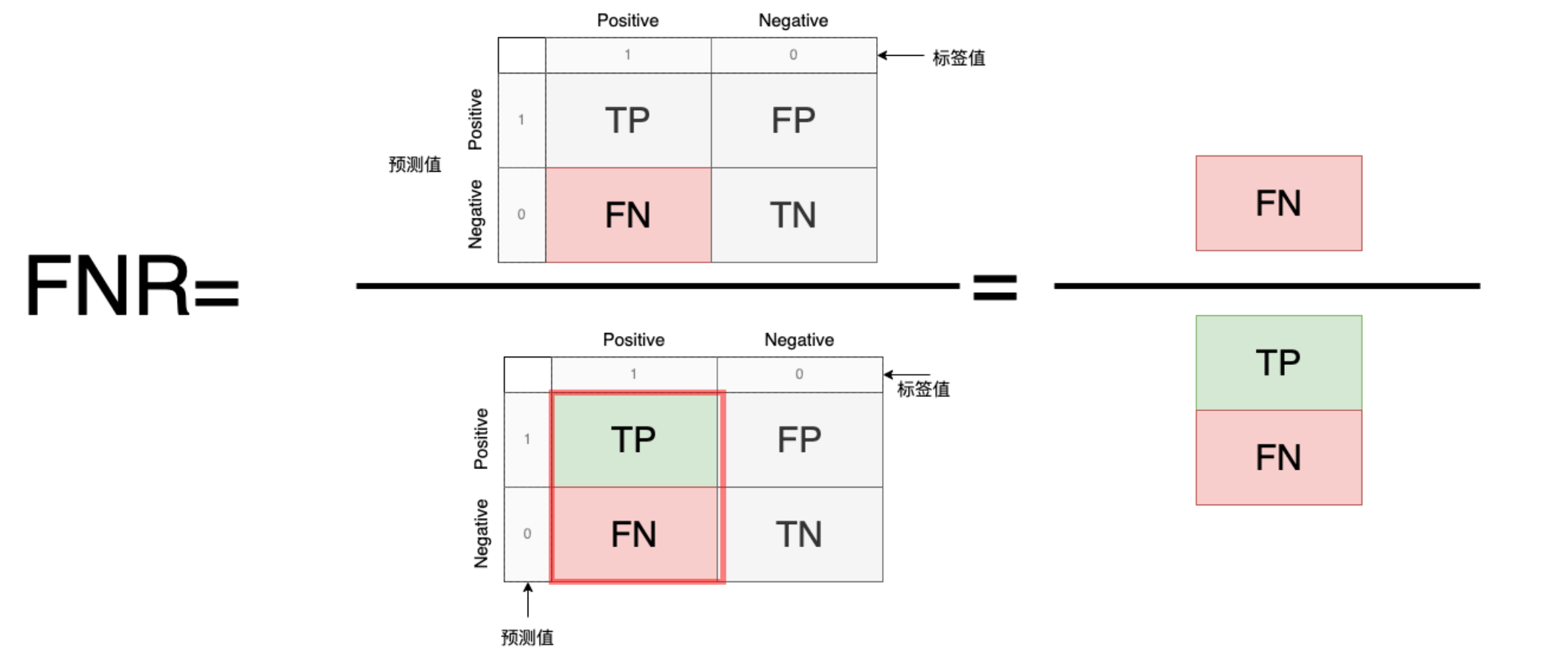
5.TPR/FNR:
TP(正确预测为正例)或者FN(正例错误预测为负例)分别占标签值的比例
TPR=\frac{正确预测的正例数量}{标签的正例数量}=\frac{TP}{TP+FN}\\
FNR=\frac{错误预测的正例数量}{标签的正例数量}=\frac{FN}{TP+FN}=1-TPR
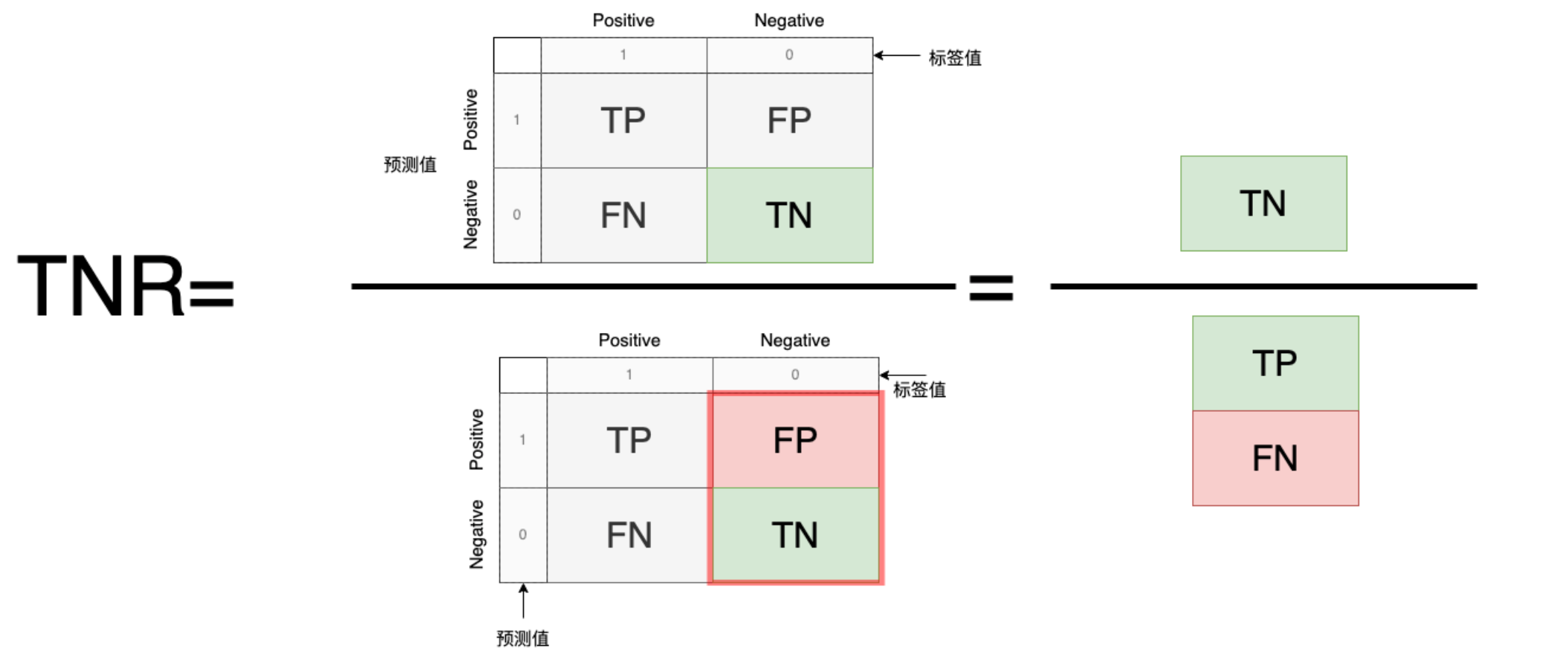
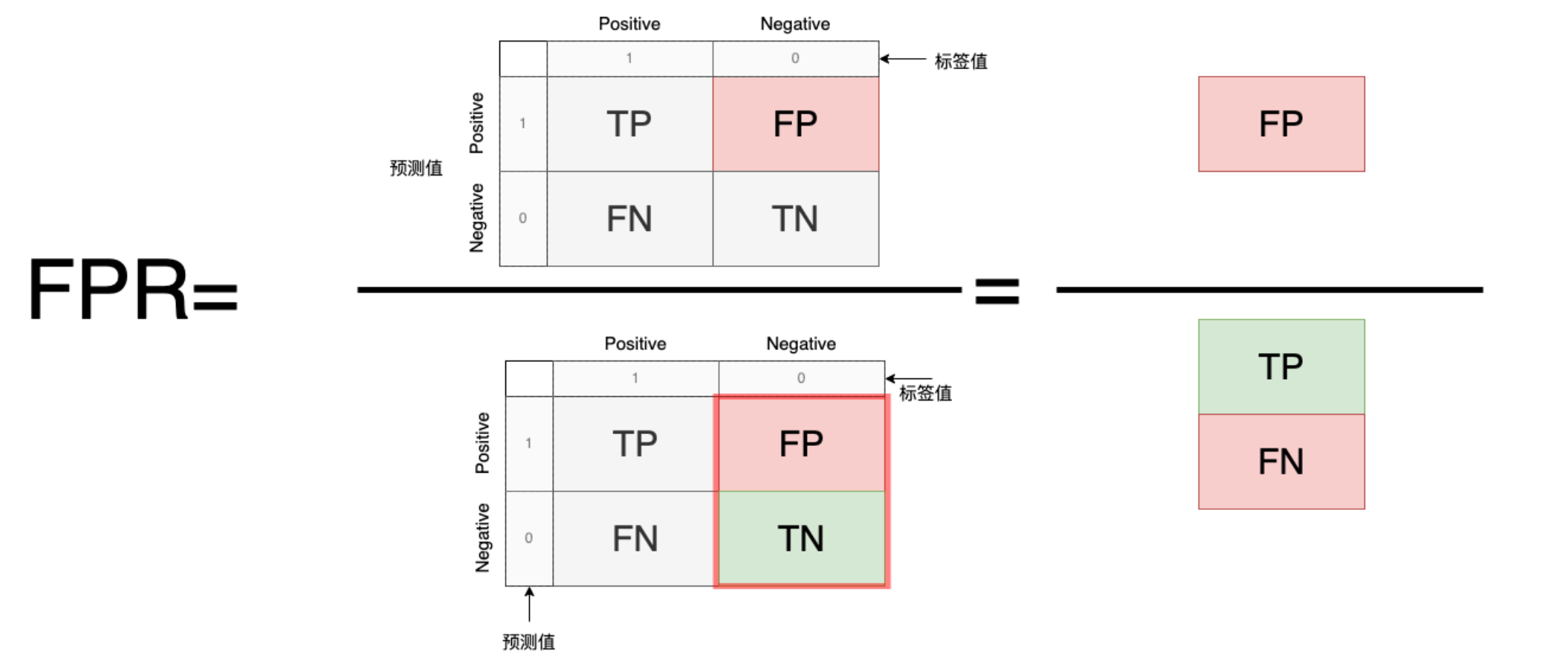
6. TNR/FPR:
TN(正确预测为负例)或者FP(负例错误预测为正例)分别占标签值的比例
留言