
Anchor-free Oriented Proposal Generator for Object Detection
概要
该论文提出了一种新的方法来解决面向对象检测中的倾斜框检测问题。传统方法使用水平框来推导出倾斜框,但水平框往往与真实标注的交并比较小,引入了冗余噪声、不匹配和降低检测器的鲁棒性等问题。为了解决这个问题,论文提出了一种不依赖水平框的Anchor-free Oriented Proposal Generator (AOPG)方法。OPG首先通过一个基于无anchor的粗定位模块(Coarse Location Module,CLM)产生粗略的方向框,然后将其细化为高质量的方向性提案。最后,使用Fast R-CNN头来生成最终的检测结果。此外,为了缓解大规模数据集的不足,该论文基于DIOR数据集发布了一个新的数据集DIOR-R。在大量实验中,该方法在DIOR-R、DOTA和HRSC2016数据集上分别实现了64.41%、75.24%和96.22%的mAP精度,证明了该方法的有效性。
I INTRODUCTION
II RELATED WORK
III OUR APPROACH
A. Horizontal-Box Scheme V.S. Oriented-Box Scheme
在介绍我们的模型之前,我们比较了水平框架与倾斜框架在定向目标检测中的IoU分布和回归目标分布。为此,我们在DOTA数据集上分别基于水平框架和倾斜框架训练了Faster R-CNN和我们的AOPG模型。首先,我们随机选取5000个正样本提案,并计算它们与真实边界框的IoU。水平提案和倾斜提案的IoU分布如图3(a)所示。从图中可以看出,大多数水平提案的IoU小于0.5,而所有倾斜提案的IoU均大于0.5,这得益于倾斜框架的分配方式。这表明水平提案无法与真实边界框准确匹配。此外,水平提案倾向于与真实边界框的IoU较小,这意味着其中存在背景区域或不相关的物体,这显然会降低分类和回归的准确性。
此外,我们计算了这两种检测器的回归目标并给出了它们的分布,以水平提案和倾斜提案的高度和宽度目标值表示,分别如图3(b)和图3(c)所示。很明显,水平提案的目标值不对称地分布在原点周围,还有很多样本需要进行极端的回归目标值调整,这些问题将增加检测器的训练难度。相比之下,倾斜提案的目标值如图3(c)所示,规则且小,更适合检测器进行学习。
根据比较结果,我们认为在检测器中涉及水平框架会降低最终定向目标检测的准确性。因此,有必要丢弃检测器中与水平框架相关的操作。这项研究激励我们设计了AOPG,一种生成高质量倾斜提案的新框架。
B. 粗定位模型(CLM)
旋转框定义
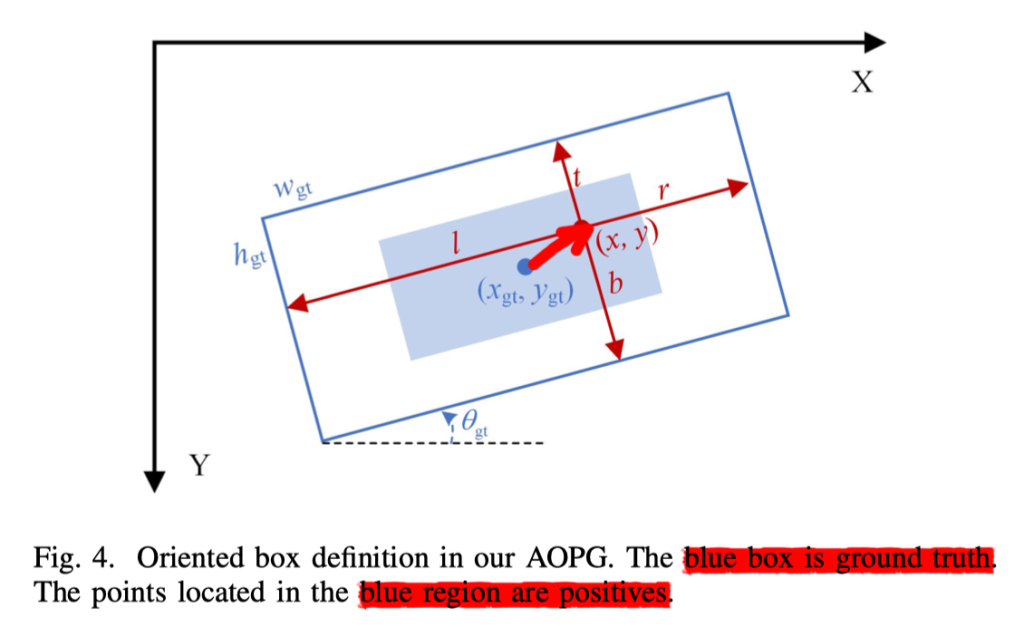
就像图4所描述的那样,我们定义一个旋转的标签值为
(x_{gt},y_{gt},w_{gt},h_{gt},θ_{gt})其中,(x_{gt},y_{gt})表示中心的坐标,w_gt 和 h_gt 表示宽度和高度,θ_gt 是顺时针旋转的其中一侧与x轴的夹角,范围是[−π/4 , π/4 ]。
给定一个正样本用(x,y)表示,他的距离向量为
t_{gt}=(l,t,r,b)分别代表着左,上,右,下 。
区域分配
基于锚框的检测器在锚框和标签值用 IOUs 来分配正样本和副样本。但是我们的CLM旋转框直接用点来预测回归 ,所以模型中是没有锚框的。因此,我们用一个区域分配的方式来取代传统的IOU分配。在训练阶段,每一个标签值将首先根据框的大小分配一个FPN(金字塔网络)的特征图。接着,我们投射特征图回原图中然后选择在标签值中心区域的为正样本区域,其他的为副样本区域。
特别地,我们使用特征图的五个层次定义为
{\{P_2,P_3,P_4,P_5,P_6\}}他们的步长分别为
{\{s_2,s_3,s_4,s_5,s_6\}}他们的值分别是 4,8,16,32,64。尺寸为[α^2s_i^2/2,2α^2s_i^2]被分配给P_i, 其中,α是放大这个范围的参数。特别地,我们设置最小的标签框值P2为0,最大的值P6为100000 来覆盖所有不同尺寸的标签框大小。
在分配每一个标签框给他们对应的特征图后,我们将位于标签值中心区域的点标记为正样本。中心标签区域可以被表示为
B_σ = (x_{gt},y_{gt},σw_{gt},σh_{gt},θ_{gt})其中,σ是中心区域的一个比例(也就是在中心内缩小多少为核心区域,图4蓝色部分)。为了判断一个点是否在在Pi中的B区域,我们需要将这个点从图像坐标系转变成标注框坐标系通过如下公式:
\left(
\begin{matrix}
x'\\
y'
\end{matrix}
\right)
=
\left(
\begin{matrix}
cosθ_{gt}&-sinθ_{gt}\\
sinθ_{gt}&cosθ_{gt}
\end{matrix}
\right)
\left(
\begin{matrix}
x-x_{gt}\\
y-y_{gt}
\end{matrix}
\right)(这里是矩阵的旋转公式,主要是将图像的坐标系转变成以蓝色框为坐标系,且在 x_{gt},y_{gt} 这个点的地方是0,0)
如果点的坐标满足|x'|< σ w_{gt} / 2 , |y'|< σ h_{gt} / 2 ,这个点在这个区域里面,那么他为正样本,就像图4中蓝色部分一样。
训练
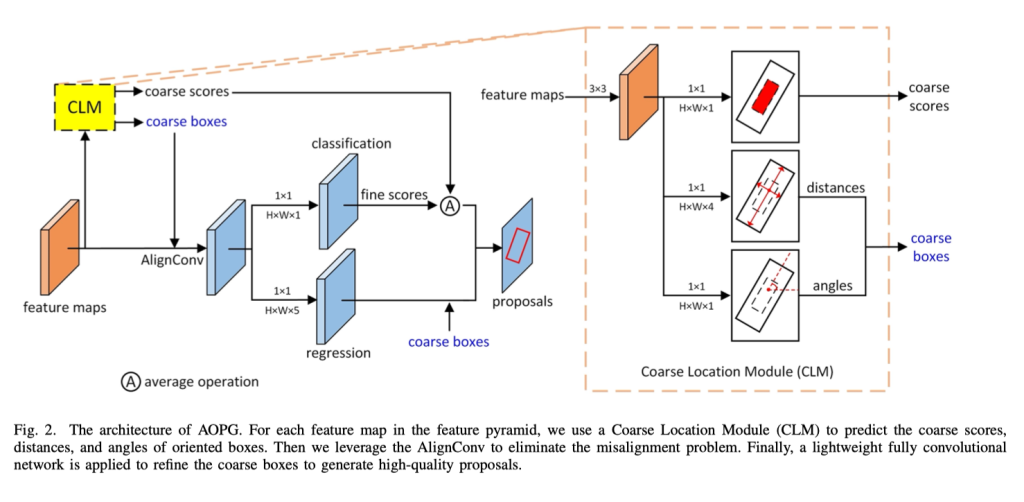
如图2所示,我们的CLM有三个分支,每一个位置分别产生粗旋转框成绩、距离(也就是距离向量)、角度,我们用 c,t,θ 来表示。
粗旋转框成绩分支是一个分类的分支,用来表明在标签框中心区域的概率,我们使用通过上述区域分配获得的所有点来训练该分支。
距离向量分支用来预测每个在特征图的点到 左,上,右,下 的标签框的距离。因为标签框坐标系系统和图片坐标系系统不平行,所以我们需要用和区域分配同样的方式将特征图转化到标签框坐标系系统。我们可以看见图4这个标签框点(x,y)的距离向量
t_{gt}=(l,t,r,v)可以通过下面公式来计算
\begin{cases}
l=w_{gt}/2+x',\quad r=w_{gt}/2-x' \\[2ex]
t=h_{gt}/2y',\quad b=h_{gt}/2-y'
\end{cases}我们训练距离分支通过归一化的距离向量
t^*_{gt}=(l^*,t^*,r^*,b^*)\\
t^*_{gt}=log(t_{gt}/z)其中,z是每个特征图中定义的归一化因子。
在定向框的定义中,角度在对称区间内,也就是 θ_{gt} ∈ [−π/4, π/4]。因此,我们直接使用真实角度作为目标来训练角度分支。所以,我们的损失函数定义如下:
L_{CLM}=\frac{λ}{N}\sum_{(x,y)}L_{ctr}(c,c^*_{gt})+\frac{1}{N_{pos}}c^*_{gt}L_{dist}(t,t^*_{gt})+\frac{1}{N_{pos}}c^*_{gt}L_{angle}(θ,θ_{gt})其中, L_{ctr}是焦点损失像[26]的那样,L_{dist}和 L_{angle} 是像[5]平滑的L1损失.N是在特征图上所有点的数量,N_{pos}是正样本的个数,c^*表示通过区域分配方案获得的点标签,当一个点为正样本时,c^*为1,否则为0。
通过结合距离和角度,CLM 可以在每个位置生成一个定向框。在第 IV.C 节中,我们将粗略的定向框与 RPN 生成的水平提议进行比较,结果显示粗略的定向框比手动创建的 旋转框 要好得多。
C. 旋转框调优
接下来,我们使用一个小型的全卷积网络来识别前景并精确地调整粗略的定向框。然而,锚点框在整个特征图上是均匀分布的,并且在每个位置上有相同的形状和尺度。而我们的粗略定向框在不同位置上是变化的,这在一致的特征图中可能存在对齐不良的问题(这里我的理解是所有的候选框在每个位置的特征图是相同的,但是粗略定向框在同一个位置可能有旋转等情况,所以可能存在对齐不良的情况)。在本工作中,我们应用了一种称为 AlignConv 的特征对齐技术来将特征与粗略的定向框对齐。经过对齐后,我们生成高质量的定向提议,以进行精确的分类和位置定位。
(ChatGBT:这个句子的意思是,锚点框在整个特征图上是固定的,即它们的形状和尺度在不同的位置上都是相同的,而粗略的定向框在不同的位置上具有不同的形状和尺度。这就导致了一个问题:锚点框和粗略的定向框之间可能存在对齐不良的问题,因为锚点框是固定的,不能很好地适应不同位置上的目标,而粗略的定向框则更好地贴合目标的实际形状。这种不良的对齐问题会导致后续处理中的误差和降低检测的准确性。因此,在这个工作中,作者提出了一种特征对齐技术 "AlignConv" 来解决这个问题。)
用AlignConv来对齐特征图
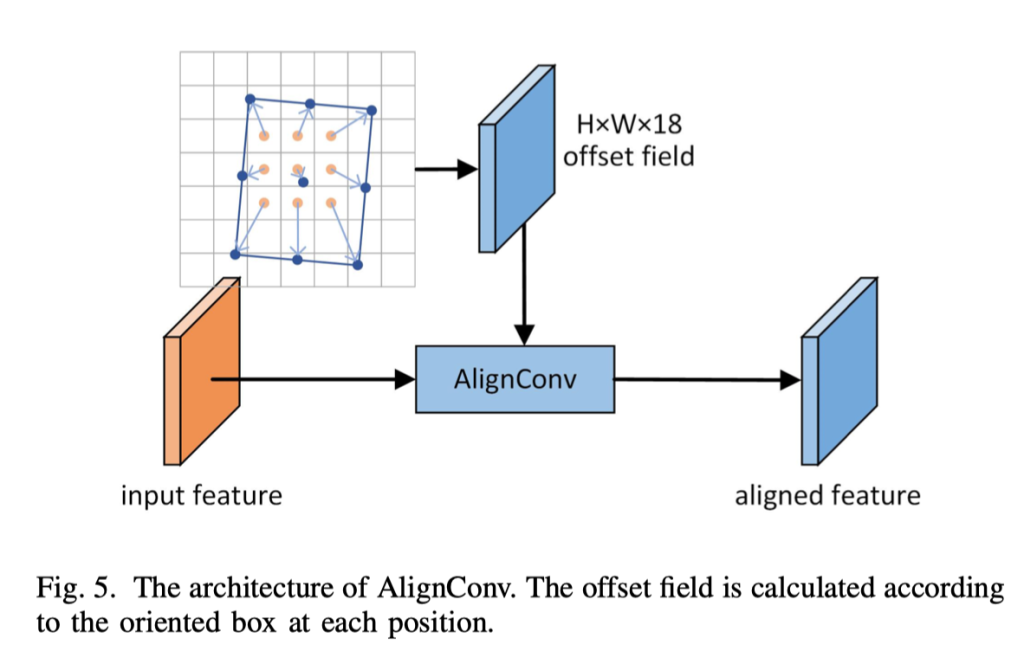
就像图5所示的AlignConv结构,AlignConv的主要部分是一个可变形卷积层,它通过偏移场对输入特征进行对齐。与从小型网络生成偏移场的普通可变形卷积不同,AlignConv从定向框中推导出偏移场。具体地,对于一个位置向量p∈ { 0, 1, ..., H − 1 } × { 0, 1, ..., W − 1 } ,一个标准的3×3可变形卷积可以表示为
Y(p)=\sum_{r∈R}W(r)·X(p+r+o)其中,X、Y是输入和输出特征图,W是可变形卷积的权重,r是自己规则网格的元素向量(这里是标准卷积公式里的)
R = { (−1, −1), (−1, 0), ..., (1, 1) }(这里我的理解是中心网格是0,0,然后第一个格子是-1,-1,W是权重,是一个矩阵,然后在-1,-1的权重值乘上X是输入的图像的(-1,-1)这个地方,这里用的是3x3的卷积;而可变形卷积就是在这个基础上加上我们学到的偏移量o,比如在
o是位置偏移量(这里是用可变形卷积来实现的,主要是多了两个卷积核,也就是2层卷积分别代表x、y偏移量的值,这个值是通过学习得来的)
注:可变形卷积图示
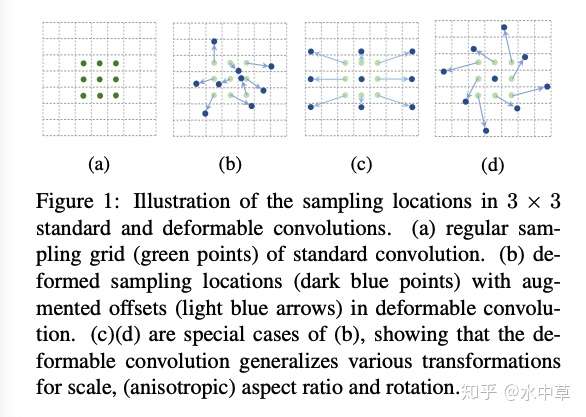
在AlignConv中,我们限制采样点在粗略定向框B=(x,y,w,h,θ)内服从规则分布(表示样本点在粗略定向框内均匀分布),如图5所示。这个采样点可以用如下公式推导得出:
r_{box}=\frac{1}{s_i}((x,y)-p+(\frac{w}{2},\frac{h}{2})·r) R^T(\theta)其中,R(θ)是和[4]一样的旋转矩阵,Si是特征图的步。我们可以通过以下公式计算位置p处的偏移场O:
O=\sum_{r∈R}(r_{box}-p-r)高质量的有方向性提议
特征对齐后,我们分别应用两个1×1卷积层生成分类和回归映射,以识别前景和优化有方向的框。对于提议的优化,我们需要先计算粗略框与标注框的IoU值来分配它们的标签。这里,粗略框是通过CLM生成的。IoU大于0.7的框被视为正样本,小于0.3的框被视为负样本。其他框则被忽略。通过定义正样本和负样本,可以将粗略框优化到准确的位置,生成高质量的有方向性提议。
旋转目标检测
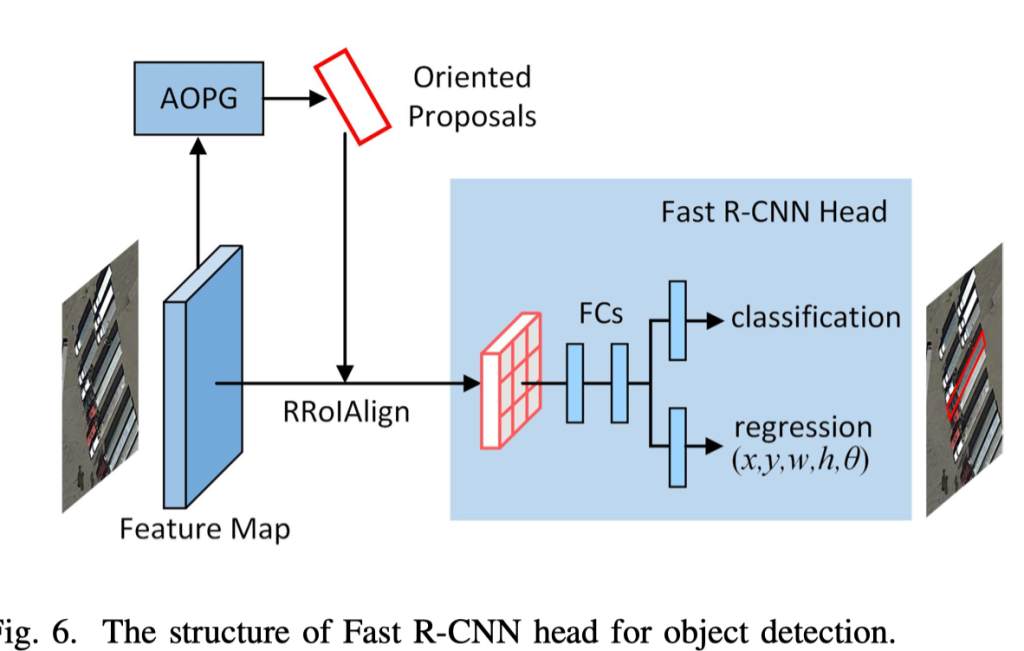
就像图6所表示的那样,我们采纳修改过的Fast R-CNN 头在第二个阶段来预测分类的分数和回归最后的选择框。不同于原来的Fast R-CNN投,我们在回归分支加入了一个角度的参数来预测角度。详细的AOPG可以在我们发布的代码里面找到。
我觉得可以改进的地方
- 更好的特征提取器:该论文的方法使用的是 ResNet50-FPN 作为特征提取器。但是近期还有许多其他的更先进的网络结构和特征提取器,比如 Swin Transformer 和 ViT 等。因此,尝试使用这些新的特征提取器,可能会有更好的结果。
- 更好的回归器:该论文中使用的回归器是标准的二维回归器。但是,一些新的回归器,比如 CenterNet 和 RepPoints,已经在目标检测中取得了很好的表现。因此,将这些新的回归器集成到该方法中可能会带来更好的结果。
- 多任务学习:该论文中的分类和回归任务是独立进行的,但是多任务学习已经被证明可以带来更好的性能。因此,将这两个任务组合成一个多任务学习模型,可能会有更好的效果。
留言